
引き続き、
株とPython─自作プログラムでお金儲けを目指す本 (技術の泉シリーズ(NextPublishing))
こちらの本のコードを利用させてもらっています。違いは、この本では、有料のサイトからデータをスクレイピングしていますが、僕は無料のサイトを使っています。
ですので、データは同じはずですがCSVの形式が異なっているので、本のコードそのままは使えません。
そこで、自分がつまずいたことなどを後から見返せるようにと、まとめていきます。
また、本のコードは、電子書籍の試し読みからでも公開されているので、ぜひ見てみてください。
株式投資メモでダウンロードしたCSVからデータをpythonで抽出する
株式投資メモからCSVをダウンロードする方法についてはこちらの記事で紹介しています。

例えば、ダウンロードした「株コード1301の2000年」のCSVデータはこんな感じでした。
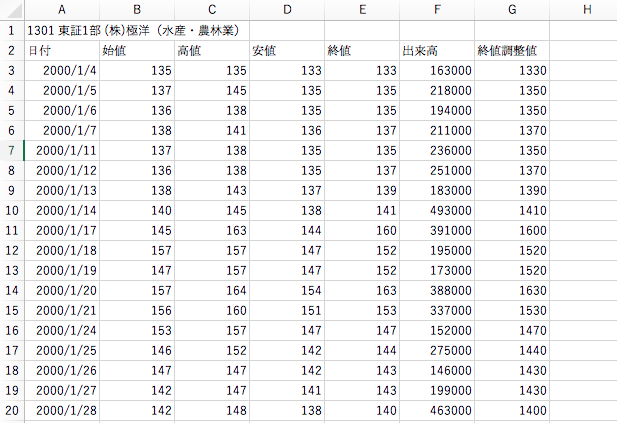
1つのCSVからデータを抽出する関数
まずは、このファイルからデータを抽出する関数です。
import csv
import glob
import datetime
import os
import sqlite3
def generate_price_from_csv_file(csv_file_name,code):
with open(csv_file_name, encoding="shift_jis")as f :
reader = csv.reader(f)
next(reader) #一行目をとばす
next(reader) #二行目もとばす
for row in reader:
d=datetime.datetime.strptime(row[0],'%Y-%m-%d').date() #日付
o=float(row[1]) #始値
h=float(row[2]) #高値
l=float(row[3]) #安値
c=float(row[4]) #終値
v=float(row[5]) #出来高
yield code,d,o,h,l,c,v
with open(csv_file_name, encoding=”shift_jis”)as f :
で「encoding=”shift_jis」を指定しないと、
'utf-8' codec can't decode byte 0x93 in position 5: invalid start byte
というエラーメッセージがでます。「’utf-8’という文字コードは読み込めませんよ」みたいですね。
なので、文字コードを変換する必要があるようです。
次のようにして呼び出します。
#格納させているPATH
csv_dir= '/Users/<ユーザーネーム>/Desktop/KabuPython/raw_prices_for_selenium'
#PATHで指定したフォルダにあるCSVファイルがpathにリストで格納する
path=glob.glob(os.path.join(csv_dir,"*.csv"))
#pathの最初のやつ
csv_file_name=path[0]
code=1301
for i in generate_price_from_csv_file(csv_file_name,code):
print(i)generate_price_from_csv_file(csv_file_name,code)はジェネレーターなので、for文で回さないと、値を取り出すことができません。
この辺は「ジェネレーター 値 取り出し方」や「yield 使い方」などで調べれば理解が深まると思います。
と言いながら僕はまだまだ曖昧なまま進んでる気がする。。。
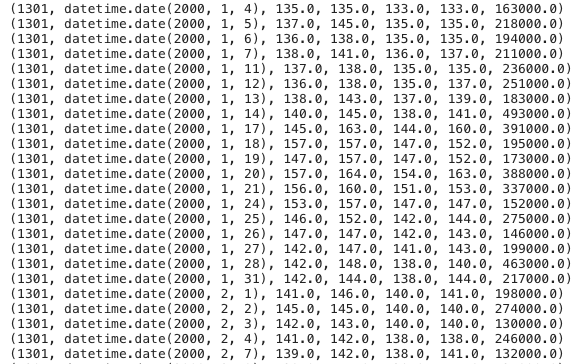
このように取り出すことができました。
複数のCSVからデータを抽出する関数
複数のCSVデータを一気に抽出したい場合は次の関数を追加します。これもジェネレーターです。
def generate_from_csv_dir(csv_dir):
for path in glob.glob(os.path.join(csv_dir,"*.csv")):
file_name=os.path.basename(path)
code_year=code=file_name.split('.')[0]
code=code_year.split('_')[0]
for d in generate_price_from_csv_file(path,code):
yield d呼び出し方は、
csv_dir= '/Users/<ユーザー名>/Desktop/KabuPython/raw_prices_for_selenium'
for i in generate_from_csv_dir(csv_dir):
print(i)とします。
抽出したデータをSQLiteに格納する
データを扱いやすくするためにSQLiteに格納していきます。
データベースには次のテーブルを作成しています。
CREATE TABLE “raw_prices” (
“code” TEXT,
“date” TEXT,
“open” REAL,
“hight” REAL,
“low” REAL,
“close” REAL,
“volume” INTEGER,
PRIMARY KEY(“code”,”date”)
);
次にpythonで使用する関数です。
def all_csv_file_to_db(db_file_name,csv_file_dir):
price_generator = generate_from_csv_dir(csv_dir)
conn = sqlite3.connect(db_file_name)
with conn :
sql = """
INSERT INTO raw_prices(code,date,open,hight,low,close,volume)
VALUES(?,?,?,?,?,?,?)
"""
conn.executemany(sql,price_generator)
最後の行の
conn.executemany(sql,price_generator)
というところですが、
「price_generator」には、上で紹介した「複数のCSVからデータを抽出する関数(ジェネレーター)」が入っています。
つまり、.executemany()メソッドの引数にジェネレーターを入れた場合、勝手に?展開してくれるんですね。よくできているなぁ。
次のようにして呼び出して、実行します。
csv_dir= '/Users/<ユーザー名>/Desktop/KabuPython/raw_prices_for_selenium'
db_file_name='price.db' #データベース(DB)のファイルです。実行ファイルと同一ディレクトリーにいます
all_csv_file_to_db(db_file_name,csv_dir)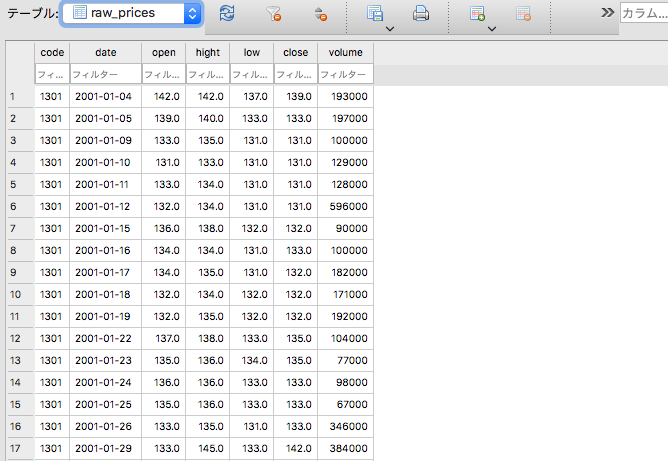
無事データが入りました。


コメント