こちらのサイトのコードを参考にさせていただきました。
- 1983年〜の株価を取得できる
- 取得する株コードをリストで指定し、一括で取得できる
- ファイルの保存先を指定できる
株式投資メモからスクレイピングする方法
ヤフーファイナンスのVIP倶楽部に有料(2138円)で登録すれば、全銘柄のCSVデータをダウンロードできます。今参考にさせてもらっている株とPython─自作プログラムでお金儲けを目指す本 (技術の泉シリーズ(NextPublishing))という本でも、この方法を推してます。
ただ、お金をかけずに取得したい、、、ということで、株式投資メモ というサイトから無料ダウンロードしていきたいと思います。
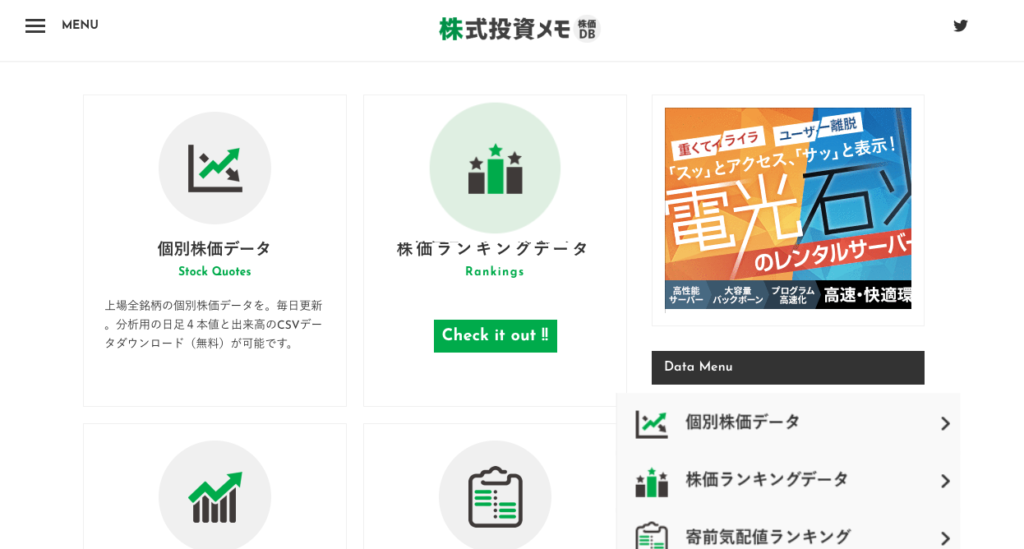
個別株価データをクリックします。

ダイワ 上場投信-トピックスのコード番号である1305を入力してみると
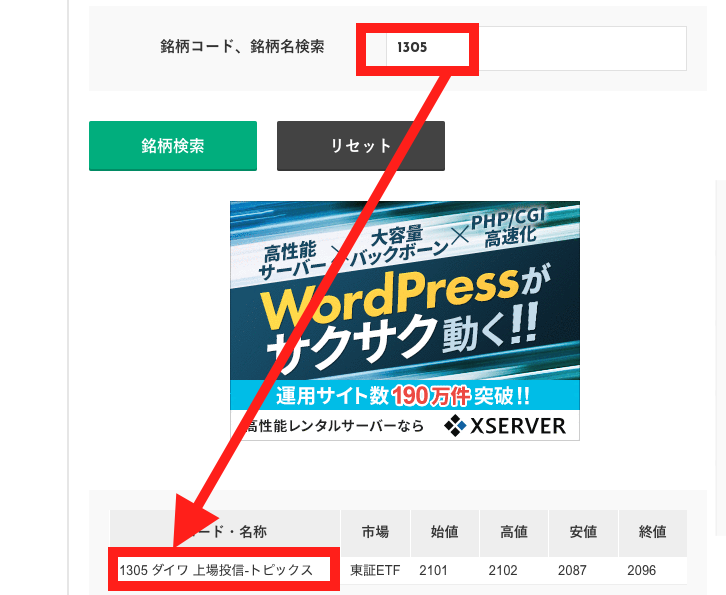
このように表示されるので、クリックすると、

このように、2001年からの日足データがダウンロードできることがわかりました。このときのURLを確認してみると
https://kabuoji3.com/stock/1305/
のようになっています。さらに、2020年を選択してみると、「CSVデータダウンロードページへ」というボタンが表示されました。

このURLは
https://kabuoji3.com/stock/1305/2020/
です。
https://kabuoji3.com/stock/{株コード}/{年}
という構造になっていることを利用して、欲しい株の情報を取得していきます。
url = ‘https://kabuoji3.com/stock/{0}/{1}/’.format(code,year)
pythonのseleniumを使ったコードを解説
まず、呼び出す関数のコードです。
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
import time
def download_stock_csv(codes,year_range):
#####codesは、株式コードをリストで渡し、year_rangeは取得年をrangeで渡す。
#---------ダウンロード先を指定してChromeを開く---------
###ダウンロード先(*^^*)
download_directory='ファイルのPATH'
#例) download_directory='/Users/<ここにユーザー名が入る>/Desktop/KabuPython/raw_prices_for_selenium'
#################
chop=webdriver.ChromeOptions()
prefs={"download.default_directory":download_directory}
chop.add_experimental_option("prefs",prefs)
chop.add_argument('--ignore-certificate-errors')
##Chromeを起動させる##
driver = webdriver.Chrome(options = chop)
#################
for code in codes:
try:
for year in year_range :
url = 'https://kabuoji3.com/stock/{0}/{1}/'.format(code,year)
driver.get(url)
try:
driver.find_element_by_name("csv").click()
time.sleep(3)
driver.find_element_by_name("csv").click()
except NoSuchElementException:
print(code,"の",year,"年がありません")
pass
time.sleep(1)
except NoSuchElementException:
print("no code")
pass
time.sleep(3)
webdriver.Chrome()のoptions属性を使ってダウンロードするファイルを指定しています。
次のように関数を呼び出して、CSVファイルをダウンロードします。
download_stock_csv([1301,1302,1305],range(2000,2002))Jupiter labでの実行結果です
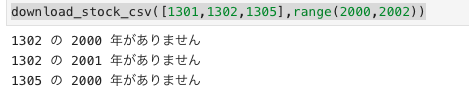
このように、存在しないコードや年を取得しようとした際には、printにて出力し、for文を止めないようにしています。
指定したファイルにダウンロードしたCSVを保存することができています。
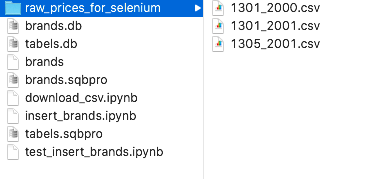
ファイルを開くと、
ダウンロードできていることがわかります。


コメント